Il existe aujourd’hui de nombreux outils capables de générer de la donnée par IA. Ceux-ci sont le plus souvent hébergés par des solutions propriétaires et ont une fâcheuse tendance à être rigides et peu transposables dès lors qu’on les implémente sur des problématiques spécifiques.

© Réalisation : R. de Matos-Machado (2021)
Pour plus de flexibilité et d’efficacité, quoi de mieux que d’entraîner soi-même son propre modèle IA à partir de librairies open source ? Après avoir exposé les grands principes de l’apprentissage profond (deep learning) dédié à la cartographie de données géospatiales (i.e. segmentation sémantique), cette présentation fournira quelques bases pratiques aux amateurs d’IA et de Python souhaitant développer leur propre modèle IA de cartographie. Elle s’inspirera de projets Github afin de favoriser la pratique en dehors de cette séance.
À lire aussi
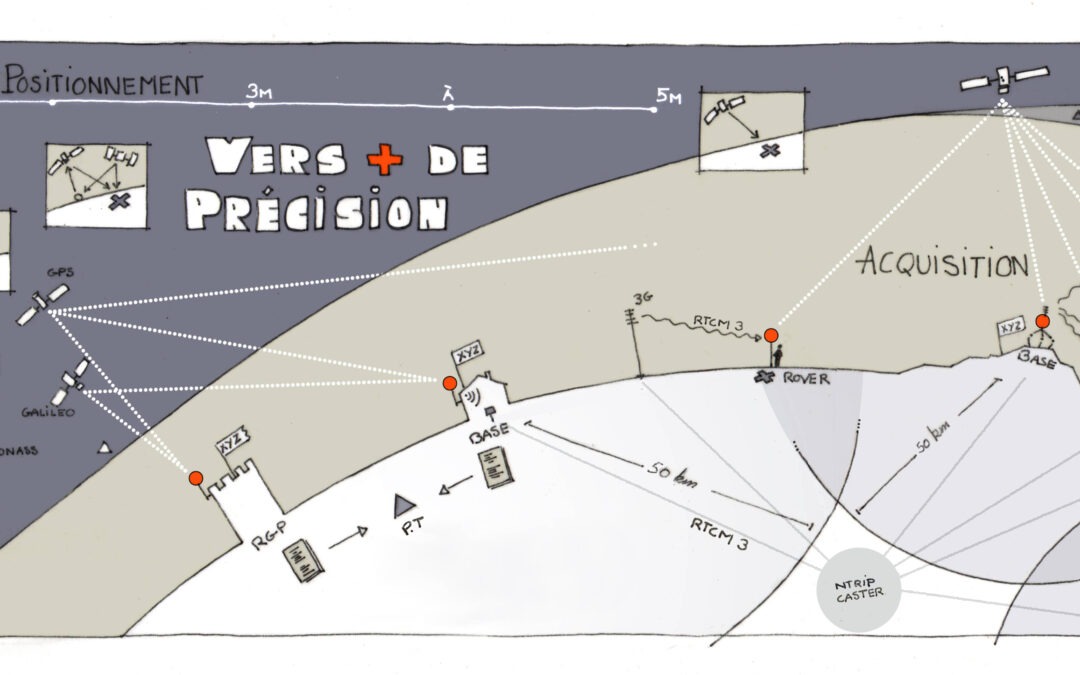
Prises de données de terrain : GPS, applis de géomatique et Centipède, utilisation comparée – théorie et pratique – mercredi 19 novembre à 9h30
L'objectif de cet atelier conjoint de Géotéca et de l'Atelier Méthodologique PRODIG est de comparer la précision et l'ergonomie des différents instruments de prise de données spatiales sur le terrain : GPS, applis telles que SWMaps, Qfield, ou bien le système de haute...

Présentation de l’ouvrage” Cartographia – Comment les géographes (re)dessinent le Monde ” par Françoise Bahoken et Nicolas Lambert – jeudi 20 novembre à 12h30
Nous avons la chance de recevoir Françoise Bahoken et Nicolas Lambert pour la présentation de leur ouvrage paru en septembre 2025 chez Dunod : Cartographia Comment les géographes (re)dessinent le Monde. La Terre est-elle vraiment ronde ? Pourquoi le Nord est-il en...

FORMATION 2025 Les bases de la GEOMATIQUE – 7-8 avril 2025
Cette formation s'adresse à tout type de public ayant des données à cartographier et qui souhaite se familiariser avec un logiciel de Système d'Information Géographique (logiciel de cartographie). Objectifs => Savoir manipuler des données dans un logiciel de...

Prochaine formation : Réaliser une carte et s’initier au SIG (système d’information géographique) avec le logiciel Q Gis
Quand : mardi 11/02/2025 et vendredi 14/02/2025, de 9h30 à 12h30 et de 14h à 17h Responsables : Cathy CHATEL et Brian PLAISANT, Ingénieurs en géographie et bases de données, Plateforme de recherche Geoteca, UFR GHES Public concerné : Etudiants tous niveaux,...